Выбор читателей




Популярные статьи
В данной статье я расскажу о том, как найти среднеквадратическое отклонение . Этот материал крайне важен для полноценного понимания математики, поэтому репетитор по математике должен посвятить его изучению отдельный урок или даже несколько. В этой статье вы найдёте ссылку на подробный и понятный видеоурок, в котором рассказано о том, что такое среднеквадратическое отклонение и как его найти.
Среднеквадратическое отклонение дает возможность оценить разброс значений, полученных в результате измерения какого-то параметра. Обозначается символом (греческая буква «сигма»).
Формула для расчета довольно проста. Чтобы найти среднеквадратическое отклонение, нужно взять квадратный корень из дисперсии. Так что теперь вы должны спросить: “А что же такое дисперсия?”
Определение дисперсии звучит так. Дисперсия — это среднее арифметическое от квадратов отклонений значений от среднего.
Чтобы найти дисперсию последовательно проведите следующие вычисления:
Рассмотрим на примере. Допустим, вы с друзьями решили измерить рост ваших собак (в миллиметрах). В результате измерений вы получили следующие данные измерений роста (в холке): 600 мм, 470 мм, 170 мм, 430 мм и 300 мм.
Вычислим среднее значение, дисперсию и среднеквадратическое отклонение.
Сперва найдём среднее значение . Как вы уже знаете, для этого нужно сложить все измеренные значения и поделить на количество измерений. Ход вычислений:
Среднее мм.
Итак, среднее (среднеарифметическое) составляет 394 мм.
Теперь нужно определить отклонение роста каждой из собак от среднего :

Наконец, чтобы вычислить дисперсию , каждую из полученных разностей возводим в квадрат, а затем находим среднее арифметическое от полученных результатов:
Дисперсия мм 2 .
Таким образом, дисперсия составляет 21704 мм 2 .
Как найти среднеквадратическое отклонение
Так как же теперь вычислить среднеквадратическое отклонение, зная дисперсию? Как мы помним, взять из нее квадратный корень. То есть среднеквадратическое отклонение равно:
Мм (округлено до ближайшего целого значения в мм).
Применив данный метод, мы выяснили, что некоторые собаки (например, ротвейлеры) – очень большие собаки. Но есть и очень маленькие собаки (например, таксы, только говорить им этого не стоит).
Самое интересное, что среднеквадратическое отклонение несет в себе полезную информацию. Теперь мы можем показать, какие из полученных результатов измерения роста находятся в пределах интервала, который мы получим, если отложим от среднего (в обе стороны от него) среднеквадратическое отклонение.
То есть с помощью среднеквадратического отклонения мы получаем “стандартный” метод, который позволяет узнать, какое из значений является нормальным (среднестатистическим), а какое экстраординарно большим или, наоборот, малым.
Но… все будет немного иначе, если мы будем анализировать выборку данных. В нашем примере мы рассматривали генеральную совокупность. То есть наши 5 собак были единственными в мире собаками, которые нас интересовали.
Но если данные являются выборкой (значениями, которые выбрали из большой генеральной совокупности), тогда вычисления нужно вести иначе.
Если есть значений, то:
Все остальные расчеты производятся аналогично, в том числе и определение среднего.
Например, если наших пять собак – только выборка из генеральной совокупности собак (всех собак на планете), мы должны делить на 4, а не на 5, а именно:
Дисперсия выборки =  мм 2 .
мм 2 .
При этом стандартное отклонение по выборке равно  мм (округлено до ближайшего целого значения).
мм (округлено до ближайшего целого значения).
Можно сказать, что мы произвели некоторую “коррекцию” в случае, когда наши значения являются всего лишь небольшой выборкой.
Но почему при вычислении дисперсии мы берём именно квадраты разностей? Допустим при измерении какого-то параметра, вы получили следующий набор значений: 4; 4; -4; -4. Если мы просто сложим абсолютные отклонения от среднего (разности) между собой … отрицательные значения взаимно уничтожатся с положительными:
 .
.
Получается, этот вариант бесполезен. Тогда, может, стоит попробовать абсолютные значения отклонений (то есть модули этих значений)?
На первый взгляд получается неплохо (полученная величина, кстати, называется средним абсолютным отклонением), но не во всех случаях. Попробуем другой пример. Пусть в результате измерения получился следующий набор значений: 7; 1; -6; -2. Тогда среднее абсолютное отклонение равно:
Вот это да! Снова получили результат 4, хотя разности имеют гораздо больший разброс.
А теперь посмотрим, что получится, если возвести разности в квадрат (и взять потом квадратный корень из их суммы).
Для первого примера получится:
 .
.
Для второго примера получится:
Теперь – совсем другое дело! Среднеквадратическое отклонение получается тем большим, чем больший разброс имеют разности … к чему мы и стремились.
Фактически в данном методе использована та же идея, что и при вычислении расстояния между точками, только примененная иным способом.
И с математической точки зрения использование квадратов и квадратных корней дает больше пользы, чем мы могли бы получить на основании абсолютных значений отклонений, благодаря чему среднеквадратическое отклонение применимо и для других математических задач.
О том, как найти среднеквадратическое отклонение, вам рассказал , Сергей Валерьевич
Одним из основных инструментов статистического анализа является расчет среднего квадратичного отклонения. Данный показатель позволяет сделать оценку стандартного отклонения по выборке или по генеральной совокупности. Давайте узнаем, как использовать формулу определения среднеквадратичного отклонения в Excel.
Сразу определим, что же представляет собой среднеквадратичное отклонение и как выглядит его формула. Эта величина является корнем квадратным из среднего арифметического числа квадратов разности всех величин ряда и их среднего арифметического. Существует тождественное наименование данного показателя — стандартное отклонение. Оба названия полностью равнозначны.
Но, естественно, что в Экселе пользователю не приходится это высчитывать, так как за него все делает программа. Давайте узнаем, как посчитать стандартное отклонение в Excel.
Рассчитать указанную величину в Экселе можно с помощью двух специальных функций СТАНДОТКЛОН.В (по выборочной совокупности) и СТАНДОТКЛОН.Г (по генеральной совокупности). Принцип их действия абсолютно одинаков, но вызвать их можно тремя способами, о которых мы поговорим ниже.




Существует также способ, при котором вообще не нужно будет вызывать окно аргументов. Для этого следует ввести формулу вручную.


Как видим, механизм расчета среднеквадратичного отклонения в Excel очень простой. Пользователю нужно только ввести числа из совокупности или ссылки на ячейки, которые их содержат. Все расчеты выполняет сама программа. Намного сложнее осознать, что же собой представляет рассчитываемый показатель и как результаты расчета можно применить на практике. Но постижение этого уже относится больше к сфере статистики, чем к обучению работе с программным обеспечением.
Мудрые математики и статистики придумали более надежный показатель, хотя и несколько другого назначения – среднее линейное отклонение . Этот показатель характеризует меру разброса значений совокупности данных вокруг их среднего значения.
Для того, чтобы показать меру разброса данных нужно вначале определиться, относительно чего этот самый разброс будет считаться - jбычно это средняя величина. Дальше нужно посчитать, насколько значения анализируемой совокупности данных находятся далеко от средней. Понятное дело, что каждому значению соответствует некоторая величина отклонения, но нас же интересует общая оценка, охватывающая всю совокупность. Поэтому рассчитывают среднее отклонение по формуле обычной средней арифметической. Но! Но для того, чтобы рассчитать среднее из отклонений, их нужно вначале сложить. И если мы сложим положительные и отрицательные числа, то они взаимоуничтожатся и их сумма будет стремиться к нулю. Чтобы этого избежать, все отклонения берутся по модулю, то есть все отрицательные числа становятся положительными. Вот теперь среднее отклонение будет показывать обобщенную меру разброса значений. В итоге, средне линейное отклонение будет рассчитываться по формуле:
a – среднее линейное отклонение,
x – анализируемый показатель, с черточкой сверху – среднее значение показателя,
n – количество значений в анализируемой совокупности данных,
оператор суммирования, надеюсь, никого не пугает.
Рассчитанное по указанной формуле среднее линейное отклонение отражает среднее абсолютное отклонение от средней величины по данной совокупности.

На картинке красная линия - это среднее значение. Отклонения каждого наблюдения от среднего указаны маленькими стрелочками. Именно они берутся по модулю и суммируются. Потом все делится на количество значений.
Для полноты картины нужно привести еще и пример. Допустим, имеется фирма по производству черенков для лопат. Каждый черенок должен быть 1,5 метра длиной, но, что еще важней, все должны быть одинаковыми или, по крайней мере, плюс-минус 5 см. Однако нерадивые работники то 1,2 м отпилят, то 1,8 м. Дачники недовольны. Решил директор фирмы провести статистический анализ длины черенков. Отобрал 10 штук и замерял их длину, нашел среднюю и рассчитал среднее линейное отклонение. Средняя получилась как раз, что надо – 1,5 м. А вот среднее линейное отклонение вышло 0,16 м. Вот и получается, что каждый черенок длиннее или короче, чем нужно в среднем на 16 см. Есть, о чем поговорить с работниками. На самом деле я не встречал реального использования данного показателя, поэтому пример придумал сам. Тем не менее, в статистике есть такой показатель.
Как и среднее линейное отклонение, дисперсия также отражает меру разброса данных вокруг средней величины.
Формула для расчета дисперсии выглядит так:
 (для вариационных
рядов (взвешенная дисперсия))
(для вариационных
рядов (взвешенная дисперсия))
 (для несгруппированных
данных (простая дисперсия))
(для несгруппированных
данных (простая дисперсия))
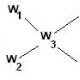
Где: σ 2 – дисперсия, Xi – анализируемsq показатель (значение признака), – среднее значение показателя, f i – количество значений в анализируемой совокупности данных.
Дисперсия - это средний квадрат отклонений.
Сначала рассчитывается среднее значение, затем берется разница между каждым исходным и средним значением, возводится в квадрат, умножается на частоту соответствующего значения признака, складывается и затем делится на количество значений в данной совокупности.
Однако в чистом виде, как, например, средняя арифметическая, или индекс, дисперсия не используется. Это скорее вспомогательный и промежуточный показатель, который используется для других видов статистического анализа.
Упрощенный способ расчета дисперсии
![]()
Среднеквадратическое отклонение
Чтобы использовать дисперсию дл анализа данных из нее извлекают квадратный корень. Получается так называемое среднеквадратическое отклонение .

Кстати, стандартное отклонение еще называют сигмой – от греческой буквы, которой его обозначают.
Среднеквадратическое отклонение, очевидно, также характеризует меру рассеяния данных, но теперь (в отличие от дисперсии) его можно сравнивать с исходными данными. Как правило, среднеквадратические показатели в статистике дают более точные результаты, чем линейные. Следовательно, среднеквадратическое отклонение является более точным показателем меры рассеяния данных, чем среднее линейное отклонение.
Материал из Википедии - свободной энциклопедии
Среднеквадрати́ческое отклоне́ние (синонимы: среднее квадрати́ческое отклоне́ние , среднеквадрати́чное отклоне́ние , квадрати́чное отклоне́ние ; близкие термины: станда́ртное отклоне́ние , станда́ртный разбро́с ) - в теории вероятностей и статистике наиболее распространённый показатель рассеивания значений случайной величины относительно её математического ожидания . При ограниченных массивах выборок значений вместо математического ожидания используется среднее арифметическое совокупности выборок.
Среднеквадратическое отклонение измеряется в единицах измерения самой случайной величины и используется при расчёте стандартной ошибки среднего арифметического , при построении доверительных интервалов , при статистической проверке гипотез , при измерении линейной взаимосвязи между случайными величинами. Определяется как квадратный корень из дисперсии случайной величины .
Среднеквадратическое отклонение:
Стандартное отклонение (оценка среднеквадратического отклонения случайной величины x относительно её математического ожидания на основе несмещённой оценки её дисперсии) :
Правило трёх сигм () - практически все значения нормально распределённой случайной величины лежат в интервале . Более строго - приблизительно с вероятностью 0,9973 значение нормально распределённой случайной величины лежит в указанном интервале (при условии, что величина истинная, а не полученная в результате обработки выборки).
Если же истинная величина неизвестна, то следует пользоваться не , а s . Таким образом, правило трёх сигм преобразуется в правило трёх s .
Большее значение среднеквадратического отклонения показывает больший разброс значений в представленном множестве со средней величиной множества; меньшее значение, соответственно, показывает, что значения в множестве сгруппированы вокруг среднего значения.
Например, у нас есть три числовых множества: {0, 0, 14, 14}, {0, 6, 8, 14} и {6, 6, 8, 8}. У всех трёх множеств средние значения равны 7, а среднеквадратические отклонения, соответственно, равны 7, 5 и 1. У последнего множества среднеквадратическое отклонение маленькое, так как значения в множестве сгруппированы вокруг среднего значения; у первого множества самое большое значение среднеквадратического отклонения - значения внутри множества сильно расходятся со средним значением.
В общем смысле среднеквадратическое отклонение можно считать мерой неопределённости. К примеру, в физике среднеквадратическое отклонение используется для определения погрешности серии последовательных измерений какой-либо величины. Это значение очень важно для определения правдоподобности изучаемого явления в сравнении с предсказанным теорией значением: если среднее значение измерений сильно отличается от предсказанных теорией значений (большое значение среднеквадратического отклонения), то полученные значения или метод их получения следует перепроверить.
На практике среднеквадратическое отклонение позволяет оценить, насколько значения из множества могут отличаться от среднего значения.
Среднее квадратическое отклонение доходности портфеля отождествляется с риском портфеля.
Предположим, существуют два города с одинаковой средней максимальной дневной температурой, но один расположен на побережье, а другой на равнине. Известно, что в городах, расположенных на побережье, множество различных максимальных дневных температур меньше, чем у городов, расположенных внутри континента. Поэтому среднеквадратическое отклонение максимальных дневных температур у прибрежного города будет меньше, чем у второго города, несмотря на то, что среднее значение этой величины у них одинаковое, что на практике означает, что вероятность того, что максимальная температура воздуха каждого конкретного дня в году будет сильнее отличаться от среднего значения, выше у города, расположенного внутри континента.
Предположим, что есть несколько футбольных команд, которые оцениваются по некоторому набору параметров, например, количеству забитых и пропущенных голов, голевых моментов и т. п. Наиболее вероятно, что лучшая в этой группе команда будет иметь лучшие значения по большему количеству параметров. Чем меньше у команды среднеквадратическое отклонение по каждому из представленных параметров, тем предсказуемее является результат команды, такие команды являются сбалансированными. С другой стороны, у команды с большим значением среднеквадратического отклонения сложно предсказать результат, что в свою очередь объясняется дисбалансом, например, сильной защитой, но слабым нападением.
Использование среднеквадратического отклонения параметров команды позволяет в той или иной мере предсказать результат матча двух команд, оценивая сильные и слабые стороны команд, а значит, и выбираемых способов борьбы.
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Для расчетов средней геометрической простой используется формула:
Для определения средней геометрической взвешенной применяется формула:
редние диаметры колес, труб, средние стороны квадратов определяются при помощи средней квадратической.
Среднеквадратические величины используются для расчета некоторых показателей, например коэффициент вариации, характеризующего ритмичность выпуска продукции. Здесь определяют среднеквадратическое отклонение от планового выпуска продукции за определенный период по следующей формуле:
Эти величины точно характеризуют изменение экономических показателей по сравнению с их базисной величиной, взятое в его усредненной величине.
Средняя квадратическая простая вычисляется по формуле:

Средняя квадратическая взвешенная равна:

размах вариации
среднее линейное отклонение
дисперсию
среднее квадратическое отклонение
Размах вариации - это разность между максимальным и минимальным значениями признака
Он показывает пределы, в которых изменяется величина признака в изучаемой совокупности.
Опыт работы у пяти претендентов на предшествующей работе составляет: 2,3,4,7 и 9 лет. Решение: размах вариации = 9 - 2 = 7 лет.
Для обобщенной характеристики различий в значениях признака вычисляют средние показатели вариации, основанные на учете отклонений от средней арифметической. За отклонение от средней принимается разность .
При этом во избежании превращения в нуль суммы отклонений вариантов признака от средней (нулевое свойство средней) приходится либо не учитывать знаки отклонения, то есть брать эту сумму по модулю , либо возводить значения отклонений в квадрат
Среднее линейное отклонение - этосредняя арифметическая из абсолютных отклонений отдельных значений признака от средней.
Опыт работы у пяти претендентов на предшествующей работе составляет: 2,3,4,7 и 9 лет.
В нашем примере: лет;
Ответ: 2,4 года.
Среднее линейное отклонение взвешенное применяется для сгруппированных данных:
Среднее линейное отклонение в силу его условности применяется на практике сравнительно редко (в частности, для характеристики выполнения договорных обязательств по равномерности поставки; в анализе качества продукции с учетом технологических особенностей производства).
Наиболее совершенной характеристикой вариации является среднее квадратическое откложение, которое называют стандартом (или стандартным отклонение). Среднее квадратическое отклонение () равно квадратному корню из среднего квадрата отклонений отдельных значений признака отсредней арифметической:
Среднее квадратическое отклонение простое:


Среднее квадратическое отклонение взвешенное применяется для сгруппированных данных:

Между средним квадратическим и средним линейным отклонениями в условиях нормального распределения имеет место следующее соотношение: ~ 1,25.
Среднее квадратическое отклонение, являясь основной абсолютной мерой вариации, используется при определении значений ординат кривой нормального распределения, в расчетах, связанных с организацией выборочного наблюдения и установлением точности выборочных характеристик, а также при оценке границ вариации признака в однородной совокупности.
| Статьи по теме: | |
|
Лимонный кекс на кефире с маком
Лимонный кекс на кефире без яиц (с пропиткой) — мой любимый рецепт к... Салат из сайры - простые и оригинальные рецепты аппетитной закуски Салат из сайры консервированной с рисом
Я очень люблю салаты с консервированной рыбой. Их можно готовить... Если во сне слышишь стук в дверь
Услышав стук в дверь, мы всегда испытываем приятное ожидание и трепетные... | |